4.1 产品Backlog管理
产品Backlog是一个经过优先级排序的产品需求的集合,每条需求最好有用户故事对它进行详细描述。一个好的产品Backlog应该具备以下几种特性:
让需求/用户故事按照优先级的顺序排序,使团队总是在处理最重要的功能。
能够随着产品逐步呈现来提供持续的计划,使计划与现实相匹配。
需求描述得足够客观与详细,使项目干系人对项目的目标作出最佳决定。
这一小节将逐一解析这些目标。
产品Backlog优先级排序
产品需求的排序过程需要在每个Sprint之前进行,下面的指南会帮助大家通过用户故事来确定需求在Backlog中的优先级:
价值:这个需求为用户产生的价值(也就是产品的商业价值)是确定产品Backlog优先级的主要标准。
成本:成本是计算ROI(投资回报率)的一个关键考虑因素,一些非常合适的功能可能因为太高的成本而不能实现,通常两个价值相等的功能排定优先级时会优先考虑成本因素。
风险:风险意味着不确定的价值和成本,随着团队提高风险层面的认知,Backlog会成为PO更好的控制工具。
认识:有时候PO/产品经理们并不非常了解一项功能的价值、风险或成本,在这种情况下可以先引入一个模型实验,这个实验品称作“Spike”(探针),如果执行探针发现成本和风险不是太大,PO/产品经理们就可以考虑提升这个需求的优先级,开始正式功能开发。
【图:Wiki中的用户故事描述包括了以上四点,并有重点标红】
经过详尽考虑上面的四点因素后,我们可以得到如下产品Backlog: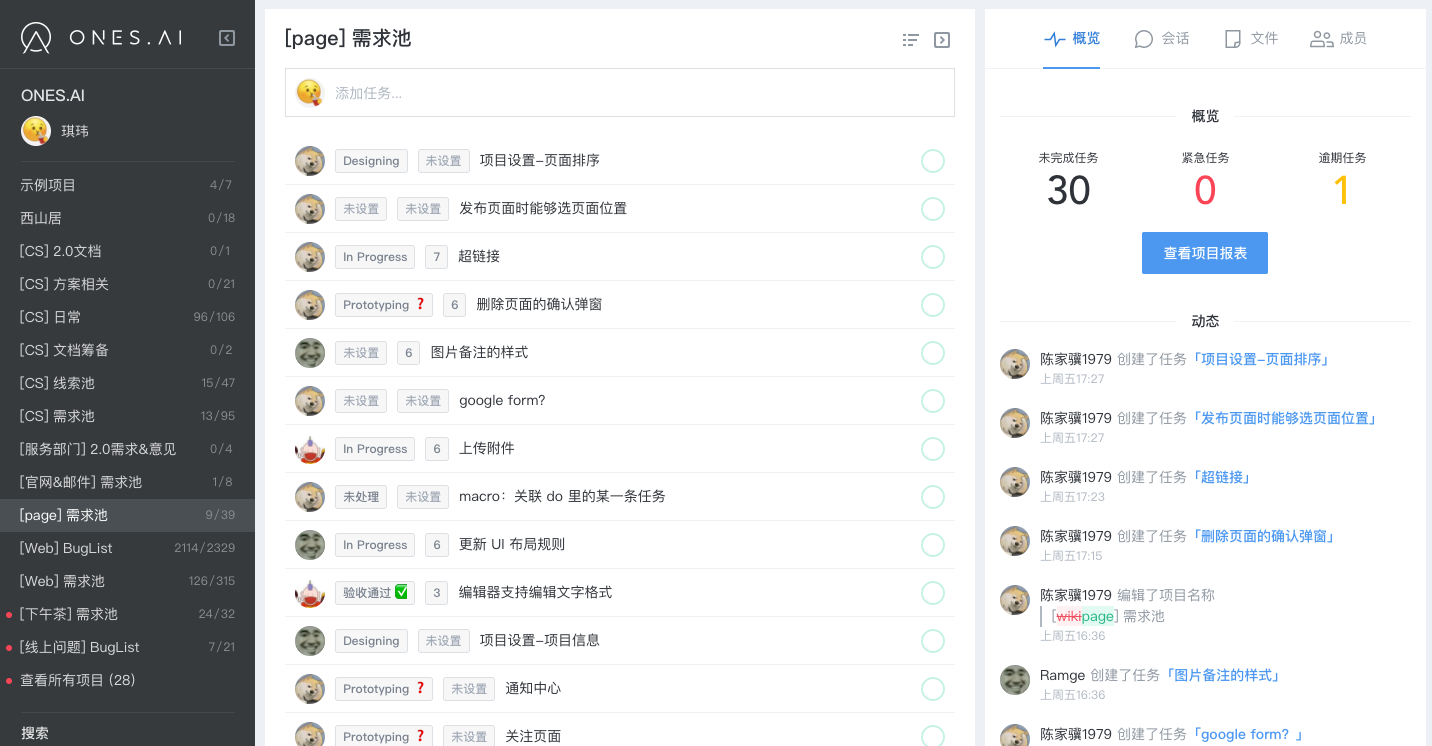 (图:产品Backlog in ONES.AI)
(图:产品Backlog in ONES.AI)
需求分解
每个Sprint之前,产品经理们需要取出产品Backlog顶端的故事,并把它们分解成一个个用小时估算的小任务。
有的时候产品需求池会有成千上万的需求,维护起来非常麻烦,所以优先级低的需求不需要太早被拆分成相同颗粒度大小的任务。对Sprint Backlog 有个非常有用的比喻叫做冰山(Cohn 2008.),最高优先级的故事用冰山顶端的雪球表示,它们同样颗粒度大小,可以在一个sprint中完成。它们下面的是优先级低的需求或者一个系列的用户故事。

(图:冰山需求模型)